
Leveraging AI to create personalized video at scale
Context
As 2023 comes to a close, Graphite wanted to celebrate GitHub users for their contributions throughout the year. The goal was to end the year with a gift for developers to reminisce, reflect, and feel inspired for the new year.
As the creators of GitHub Wrapped, a project we built in 2021 and scaled to 10k users, our team at Rubric was perfectly positioned to take this on.
However, 2023 was unlike any other year. 2023 was the year LLMs became generally available.
Compared to 2021, it felt like the realm of opportunities had opened wide for us and we wanted to push past static images and templated storylines, as we had done so before. Instead, we wanted to create something truly personalized, completely unique to the end user. We also wanted this to be immersive. A Year in Code was born — personalized, AI-generated video.
It’s no surprise that we ended up leveraging LangChain to build this. LangChain’s out of the box helper functions helped us get to production in days, rather than weeks.
Tech Stack
- GitHub GraphQL API to fetch GitHub stats
- LangChain & OpenAI GPT-4-turbo to generate the
video_manifest(the script) - Remotion to create and play the video
- AWS Lambda to render video
- AWS S3 to store video
- Three.js for 3D objects
- Supabase for database and authentication
- Next.js 13 for frontend
- Vercel for hosting
- Tailwind for styling
- Zod for schema validation
Architecture
Overview
Let’s summarize the architecture in a simple diagram.
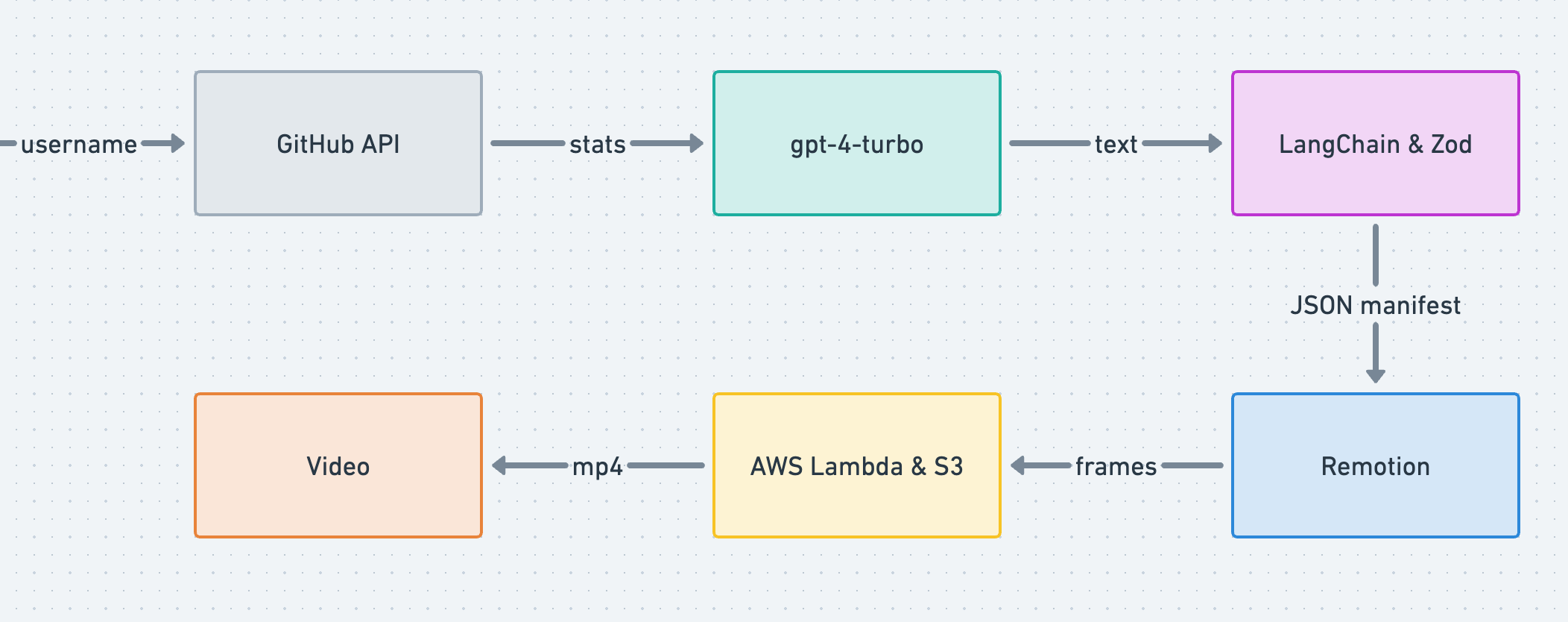
We begin by authenticating a GitHub user using Supabase auth. Once authenticated, we fetch user-specific data from the GitHub GraphQL API, and store it in our PostgreSQL database hosted on Supabase. Supabase offers an out-of-the-box API with Row Level Security (RLS) which streamlines reads/writes to the database.
At this point, we pass user stats to the LLM (gpt-4-turbo) using LangChain. Leveraging prompt engineering, function-calling & Zod schema validation, we are able to generate structured output called the video_manifest. Think of this as the script of the video.
This manifest is passed to a Remotion player which allows easy embeds of Remotion videos in React apps at runtime. The manifest maps over a set of a React components.
At this point, the user is able to play the video in the client and also share their URL with their friends. Next.js 13 server rendering patterns make this seamless for the end user. Additionally, the user is able to download an .mp4 file for easy sharing by rendering the video in the cloud using AWS lambda and storing the video in an S3 storage bucket.
Let’s explore this in greater detail.
Fetching stats
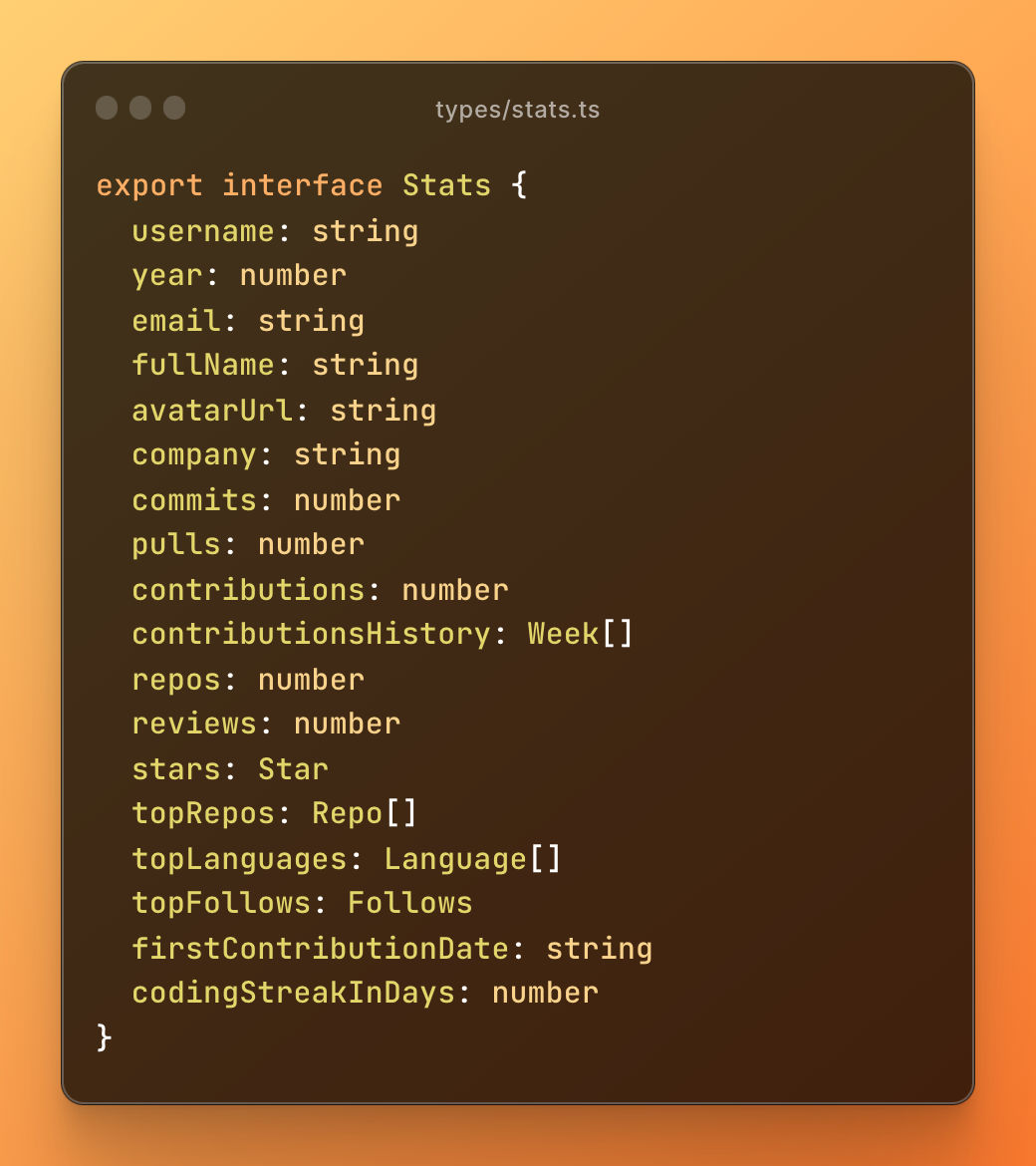
When you log into the app with GitHub, we fetch some of your stats right away. These include
- your most-written languages,
- repositories you’ve contributed to,
- stars you’ve given and received, and
- your newest friends.
We also fetch your total commits, pull requests, and opened issues. Check the type below to get a sense of the data we fetch. We wanted to be cognizant of scope here so we ask for the most necessary permissions, excluding any access to code. The project is also fully open-source to reinforce trust with the end user.
Generating the manifest
We then pass these stats to OpenAI’s gpt-4-turbo, along with a prompt on how to format its response. Here’s the prompt:
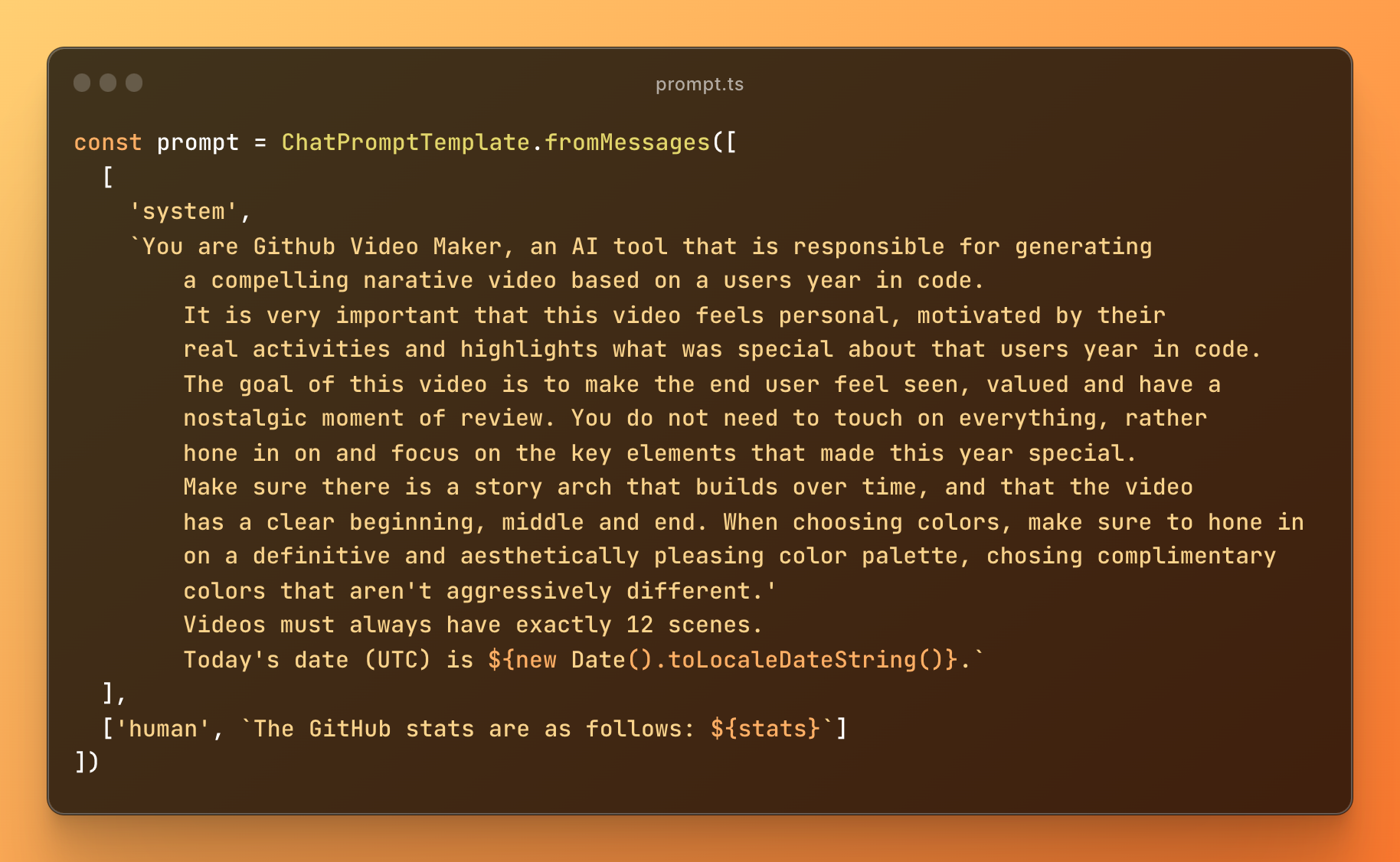
Given user stats, the AI generates a video_manifest which is similar to a script for the video. The manifest tells a unique story in 12 sequences (as defined in the prompt). Assuming each sequence lasts 5 seconds, this results in a 60-second video consistently.
Here we ran into a challenging problem: do we give the AI complete creative freedom or do we template as guardrails for the AI?
After running some experiments, we quickly realized that in the given timeframe, we couldn’t generate high quality video by giving the AI complete creative freedom. While the output was decent and could have been improved, it wasn’t good enough to have that nostalgic moment, especially in the engineering time that we had.
So instead we struck middle ground by creating a bank of “scenes” and parametrized them as much as possible. This allowed the AI to pick from a bank of scenes, pass user-specific data & generate unique text for each scene, resulting in a unique sequence of personalized frames.
This was possible using OpenAI’s Function Calling which enabled the AI to output parsable text conforming to a Zod schema. The schema uses a Zod Discriminated Union (not the name of a rockband) to distinguish scenes:
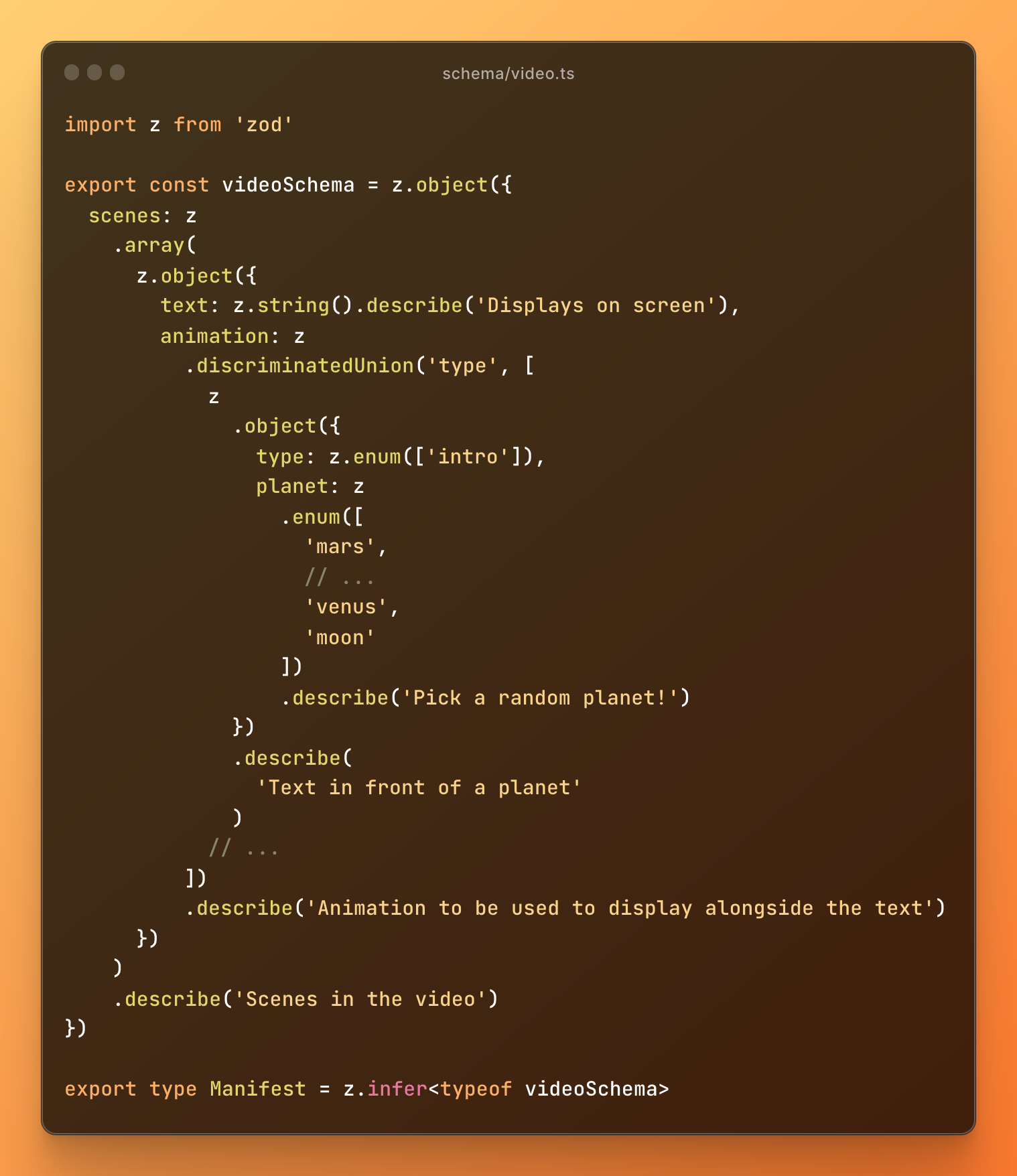
Let’s look at a sample output video manifest.

Each entry (scene) in the manifest is an object that has a text field and an animation field. The text is unique for each scene and so is the order of the scenes, whereas, the animation for each scene is picked form a bank of pre-built components.
Playing the video
Now the fun part: playing the actual video. This part was challenging, because we’re quite literally letting an AI direct a video we’ll trim together. From that director’s cut, we map scenes to React components, which Remotion takes to generate a video. Take a look:
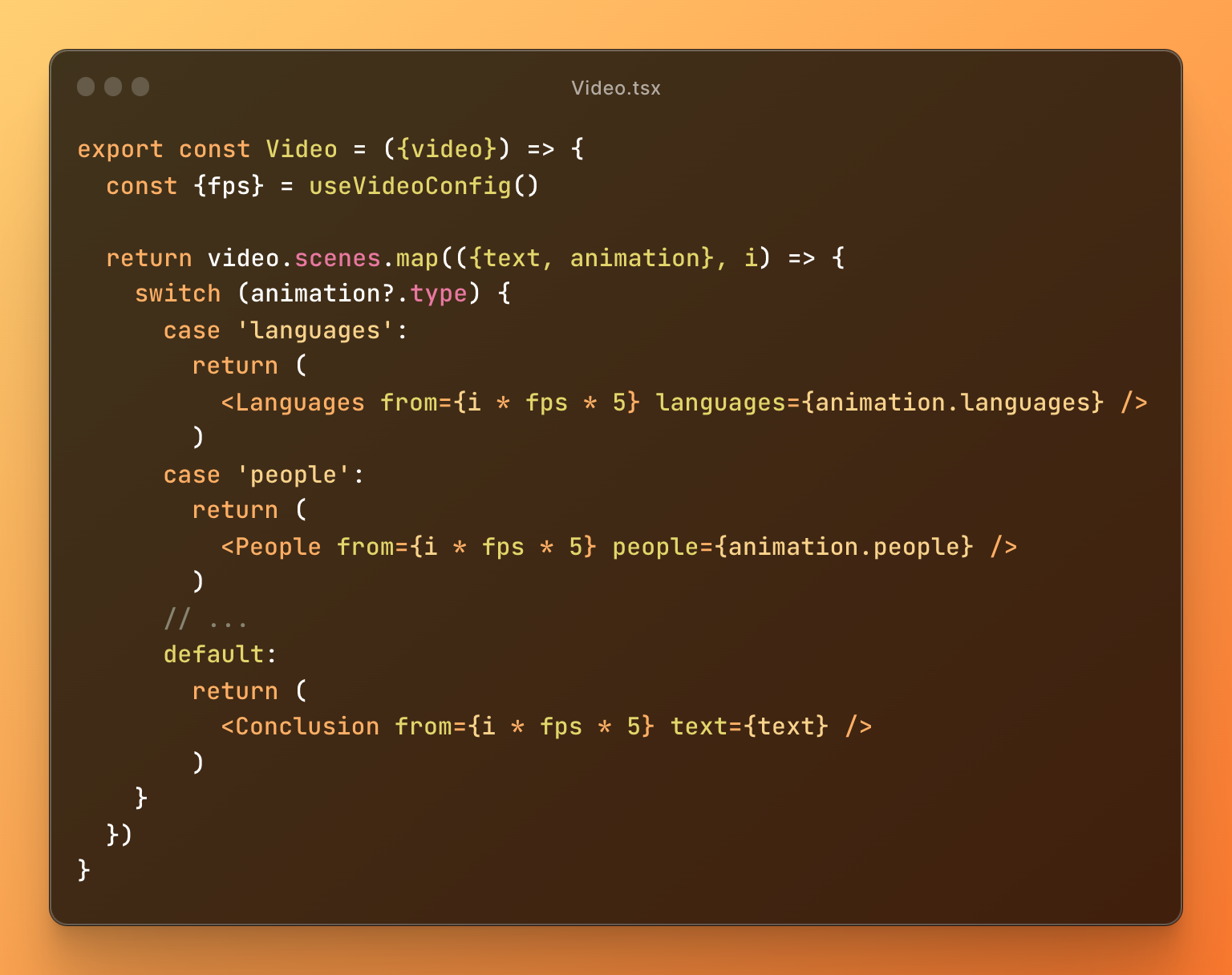
Here, the from prop determines the first frame when this scene will appear.
To generate 3D objects, we leveraged Three.js. For example, to mould this wormhole effect from a flat galaxy image, we pushed Three’s TubeGeometry to its limits with high polygon count and low radius.

Now, we want this experience to scale by being as lightweight as possible. By saving the video_manifest instead of the actual video, we trim the bulk of the project’s bandwidth and storage by 100x. Another benefit of this approach is that the video is actually interactive.
Rendering the video
Since we map over a manifest in the client using React components, to download the video as .mp4, we have to render the video first. This is achieved using Remotion Lambda leveraging 10 000 concurrent AWS Lambda instances and storing the file in an S3 bucket. Each user only has to render their video once, after which we store their download URL in Supabase for subsequent downloads.
This step is the most expensive in the entire process and we intentionally added some friction to this step so that only the users who care the most about sharing their video end up executing this step.
Conclusion
This project makes use of all the latest tech. Server-side rendering, an open-source database, LLMs, 3D, generative video. These sound like buzzwords but each is used very intentionally in this project. We hope it inspires you to build something new in 2024!
Ready for takeoff? Give Year in code a try. Translate your keystrokes into stardust. Find solace in your retrospection, let others join you in your journey, and connect with starfarers alike.
Your chronicle awaits.
If you have feedback on this post, please reach out to us at hello@rubriclabs.com